Prosa.ai hadirkan inovasi terbaru Text-to-Speech Bahasa Indonesia dan Inggris

foto: freepik
Techno.id - Prosa.ai, perusahaan yang berfokus dalam pengembangan produk berbasis Artificial Intelligence (AI) dan Natural Language Processing (NLP) baru saja meluncurkan inovasi terbaru Text-to-Speech (TTS), sebuah solusi berbasis cloud yang dapat memenuhi kebutuhan dalam mengubah teks menjadi suara.
Produk TTS saat ini menawarkan peningkatan signifikan dibanding versi sebelumnya yang dirilis tahun 2021 di mana saat itu hanya terdapat tiga suara yang tersedia, dengan satu suara laki-laki dan dua suara perempuan, serta hanya mendukung TTS Bahasa Indonesia.
Pada tahun 2024, Prosa.ai menyediakan 10 suara baru, termasuk suara Bahasa Inggris, serta fitur “jeda” dan “custom voice”, fitur ini memungkinkan pengguna menciptakan hingga 40 variasi suara yang berbeda dalam waktu yang singkat dan hasilnya dapat diunduh dalam berbagai format audio yang mendukung berbagai platform, seperti video YouTube, TikTok, dan media sosial lainnya.
Prosa juga menciptakan suara yang didesain khusus untuk audiobook berbahasa Indonesia yang diberi nama karakter Dini. Karakter suara Dini ini dianggap sangat cocok untuk bercerita, karena mempunyai gaya bicara lirih dan penuh penghayatan.

Co-Founder & CEO Prosa.ai Teguh Eko Budiarto dalam keterangan resminya menyatakan, Prosa.ai juga meningkatkan inovasinya dengan menghadirkan karakter suara-suara lainnya seperti, suara Dimas (laki-laki) dengan gaya bicara formal. Lalu ada juga Dimas dengan gaya bicara ekspresif, dan Ocha (perempuan) dengan gaya bicara ramah.
Penggunaan model suara Dimas dan Ocha ini lebih cocok pada pembacaan berita (news narrator) dan voice-over. Prosa TTS dilengkapi berbagai macam fitur yang memudahkan pengguna, yaitu Speech Synthesizer (penyintesis ucapan) yang membantu memudahkan pengubahan teks tertulis menjadi sebuah ucapan. Human-sounding Voices merupakan teknologi yang memungkinkan pengguna dapat memilih karakter suara dan gaya bicara manusia yang natural.
Voice tuning adalah fitur yang dapat menyesuaikan tinggi rendahnya nada serta mengatur kecepatan berbicara. Terakhir, Flexible Audio File yaitu fitur yang dapat menghasilkan audio dalam berbagai format (WAV, MP3 dan OPUS) sehingga pengguna dapat memutar, menyimpan audio tersebut.
RECOMMENDED ARTICLE
- Cara menampilkan fitur Dynamic Island iPhone di perangkat Android
- 3 Rekomendasi ucapan Lebaran di WhatsApp untuk orang tersayang
- Cara menggunakan peta offline di Google Maps, bisa kamu coba saat mudik nih
- Cara mengatur obrolan RCS di ponsel Android, kini punya beragam fitur layaknya WhatsApp
- Begini cara melakukan panggilan audio dan video di aplikasi X
HOW TO
-

Cara terbaru buka dan mengonversi file gambar HEIC ke JPEG di Windows 10 atau 11, gampang ternyata
-
Cara terbaru buka WhatsApp saat bermain game tanpa menutup aplikasi, ini fitur yang dibutuhkan
-
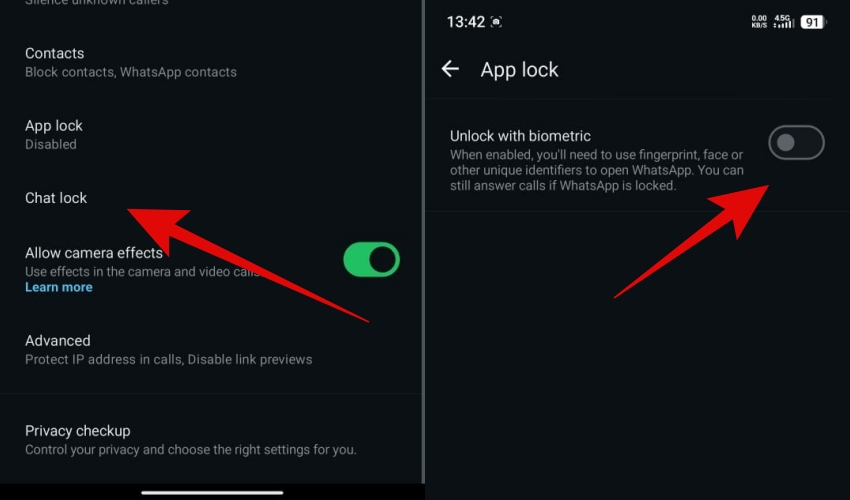
Cara mengunci chat WhatsApp (WA) dengan fingerprint atau screenlock, biar rahasia tetap aman
-
6 Cara terbaru memperbaiki Microsoft Word di Windows 10/11 yang menghapus teks dengan sendirinya
-
Cara mencari file penting di chat WhatsApp (WA) dengan cepat dan tanpa ribet



TECHPEDIA
-
Bisakah dapat Robux di Roblox secara gratis? Ini 10 faktanya agar tidak tergoda penipu
-
Detik-detik gelombang radio lawan sensor Jepang dan siarkan proklamasi kemerdekaan RI ke penjuru dunia
-
8 Penyebab charger ponsel mudah panas, jangan pakai adaptor abal-abal yang berbahaya!
-
Cara kerja peringatan dini tsunami Jepang, bisa deteksi bencana 10-20 detik sebelum datang
-
5 Tanggal Steam Sale paling populer yang termurah, game harga ratusan ribu bisa dapat diskon 90%








LATEST ARTICLE




BEST PRODUCT Selengkapnya >
-
![20 Template prompt ChatGPT untuk bikin balasan cepat WhatsApp untuk pelanggan UMKM, langsung sat-set]()
20 Template prompt ChatGPT untuk bikin balasan cepat WhatsApp untuk pelanggan UMKM, langsung sat-set
-
![7 Peluang bisnis 2025 yang memanfaatkan kecanggihan AI, gratis tanpa modal dan bisa dilakukan sekarang]()
7 Peluang bisnis 2025 yang memanfaatkan kecanggihan AI, gratis tanpa modal dan bisa dilakukan sekarang
-
![9 Aplikasi terbaru 2025 ubah gambar jadi tulisan pakai smartphone, tinggal foto langsung jadi]()
9 Aplikasi terbaru 2025 ubah gambar jadi tulisan pakai smartphone, tinggal foto langsung jadi
-
![11 Aplikasi ramalan cuaca di Android dan iPhone terbaru di 2025, akurat dan gampang memahaminya]()
11 Aplikasi ramalan cuaca di Android dan iPhone terbaru di 2025, akurat dan gampang memahaminya



